k-Nearest Twitter Neighbors
An introduction to a (relatively) intuitive algorithm

Hi! I'm Laura, and I'm a Developer Advocate at Suborbital Software Systems, formerly a math prof 🎈Team Neurodiversity 🎈Black Lives Matter 🎈She/her
Hi! I’m Laura, and I’m learning machine learning. I’m also a mathematics lecturer at Cal State East Bay, and have been fortunate to be able to work with my mentor Prateek Jain as a Data Science Fellow at SharpestMinds. This project was selected as a way for me to practice writing a machine learning algorithm from scratch (no scikit-learn allowed!) and to therefore deeply learn and understand the k-nearest neighbors algorithm, or k-NN.
The k-NN algorithm
If you’re not already familiar with k-NN, it’s a nice ML algorithm to make your first deep dive with, because it’s relatively intuitive. Zip codes are frequently useful proxies for individuals because people who live in the same neighborhood often have similar economic backgrounds and educational attainment, and are therefore also likely to share values and politics (not a guarantee, though!). So if you wanted to predict whether a particular piece of legislation would pass in an area, you might poll some of the area’s constituents and assume most of those constituents’ neighbors will feel similarly about your bill as do the majority of those you polled. In other words, if you were asked how a particular person in that district might vote, you wouldn’t know for sure how they’d vote, but you’d look at how their polled neighbors said they were going to vote, and assume your person would vote the same as the most common answer given in the poll.
Photo by Clay Banks on Unsplash
k-NN works very similarly. Given a set of labeled data and an unlabeled data point x , we’ll look at some number k of x's neighbors, and assign to x the most common label among those k neighbors. Let’s get a visual: in the image below, we have an unlabeled dot and 15 neighbors of its neighbors. Of those 15 neighbors, 9 have a magenta “A” label and 6 have a blue “B” label.
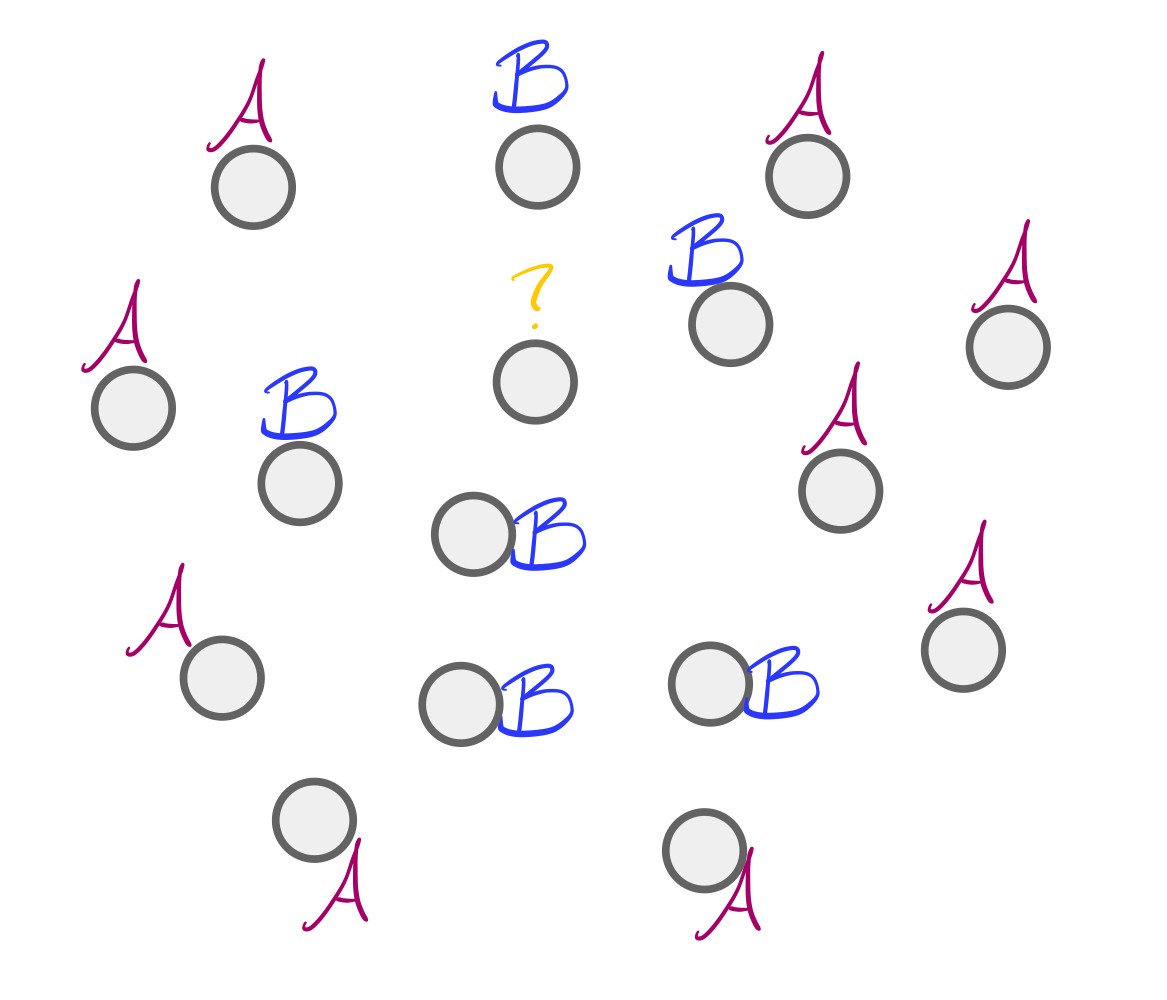
Illustration by me!
Since more of the unlabeled dot’s neighbors have an “A” label than a “B” label, we should label our dot with an “A”. And that’s k-NN!
What k-NN is not
Notice, though, what k-NN is *not*: we didn’t give our dot the label of its *closest* neighbors! Our dot is closest to the 6 “B” dots, but we didn’t call it “B”. That distinction tripped me up while I was writing my code, maybe because of the word “nearest” in the name of the algorithm? Anyway, I got all the way through writing a function that looked at a data point’s neighbors and selected the ones that were within some distance k of that data point, which is actually a different algorithm entirely: the Radius Neighbors Classifier. I should do that again and compare the results to k-NN! In another blog post, perhaps.
Something else to know about what k-NN is not is that k-NN is not a good choice of algorithm for a problem that lives in a higher-dimensional space (spoiler: this is going to end up being the punchline of this post!). Since k-NN assumes that data points “near” each other are likely to be similar, and since in a high-dimensional space the data can be spread really far apart, that notion of “nearness” becomes meaningless (for a longer explanation of this, check out this video!). Consider the islands of Australia and New Zealand: they’re each other’s closest neighbors, but they’re still thousands of kilometers apart, so they have very different climates, terrain, and ecosystems.


Left: an image of an Australian desert by Photo by Greg Spearritt on Unsplash. Right: an image of a New Zealand forest Tobias Tullius on Unsplash.
The code
Okay, so now that we know what k-NN is and what it is not, let’s have a look at the way I coded it up! Please, please note that this was explicitly an exercise for a very beginner, and it will not be as elegant or clever as the way a more experienced practitioner would do it. My instructions were to code everything from scratch, so I didn’t use Pandas to read in my data and I didn’t look at how anyone else had done it. I don’t recommend that you use my code, and I don’t need comments or emails about what you don’t like about it, because my mission was to learn this algorithm and to spend more time in my IDE instead of a Jupyter notebook, and I succeeded in those aims. :)
My mentor suggested I could use Twitter data for this project, and I needed to be able to download a large number of tweets by a single author. Ideally this author would have quite a distinct writing style, to make it easier for the algorithm to identify an unlabeled tweet as belonging to that author or not. This was the summer of 2020 and the presidential election in the states was gearing up, so my mentor thought it would be interesting to use Donald Trump as the test case (Lots of tweets? Yep. Distinctive writing style? Yep). Note: this project is definitely not an endorsement of The Former Guy, and I actually almost started over with a new batch of tweets from a different author because I don’t want to grant him any more of my headspace, but I ended up deciding against scope creep and to just get this project finished.
I found a site with all of TFG’s tweets aggregated into a txt file, and a Kaggle dataset with over 10,000 tweets by different people in a tsv file to serve as a comparison for the algorithm. Then I needed to write a function that would read the data in these files into arrays, so I could work with them.
But my data didn’t come in csv files; it was in a txt file and a tsv file! So I needed another function to convert these other file types into csv. I decided to make the function a bit more robust by including cases for several different file types:
Now I had a set of arrays with tweets from TFG and a set of arrays of tweets by other people, but if I compared them as they were I’d waste a lot of time comparing ubiquitous words like “the” or “and”, which are called “stop words” because they don’t meaningfully contribute to analysis. So I found a list of stop words and wrote a function to remove them from my arrays, and also to remove numbers and punctuation, since they wouldn’t help the analysis either. I also converted all characters to lowercase. Finally, I would need to make a “bag of words” or corpus to contain a list of all the words used in all of the tweets, and it would make sense to do that at the same time as I was cleaning the text, so I would only keep of a copy of each “cleaned” word.
Next I needed to vectorize my data so I’d be able to use NumPy functions later. To do this, I initialized a NumPy array with the same number of rows as I had tweets, with each row being as long as the number of words in the corpus + 2. I added the two extra columns so that the last column would keep track of whether the twee was written by TFG or not (1 for TFG, 0 for someone else), and the second-to-last character would store the index of the tweet so I could refer to it later during interpretation. For each tweet, my function would look at each word in the corpus and enter a ‘1’ in the column referring to that word if it appeared in the tweet, or a ‘0’ if that word wasn’t represented in that tweet. That meant these were *very* sparse arrays (mostly zeroes) — ooh, foreshadowing!
Then I needed to randomize the order of the vectors in my NumPy array so I could make training and test sets.
I split the data so that 80% went into the training set and 20% into the test set.
Getting there! Now I needed a way to compare how similar two tweets were to one another, which I would do by taking the absolute value of the difference between their vectors (absolute value because 1–0 is the same as 0–1 for this purpose, since both mean there’s a word that appears in one tweet but not the other). Each difference in words would add 1 to the “distance” between two tweets.
Now it was time to find the k-nearest neighbors! I needed to write a function that would take in a tweet vector and the number k , and compare all the other tweets to find a list of the k most similar to the tweet in question and return it.
Finally, I needed a function that would determine the most common label of the k tweets in the list returned by the previous function, which is where the 1 or 0 I’d added to the end of each tweet to indicate the author would come in handy.
So yay, we did it! It turns out, though, that my program classifies every tweet I throw at as having been written by TFG, even when I know for sure it wasn’t.
Womp womp trombone Gif (via https://media.giphy.com/media/D0feQxfAek8k8/giphy.gif)
The part where it doesn't work, and that's fine
I realized the sparseness of the tweet vectors meant that — kind of like Australia and New Zealand — two tweets being each other’s closest neighbors didn’t mean the tweets were actually very similar to one another at all. But that was okay! The purpose of this project was to get my hands dirty writing kNN from scratch and learning to process data without Pandas. (I also learned how to pickle my data once I’d processed it once, how and why to use type casting in my functions, and how to use Sphinx to create documentation for my project — though it’s not quite working properly yet. Still learning!). So this project served its purpose, even if the accuracy rate ended up being terrible.
I hope you enjoyed this stop on my learning journey! Feel free to check out previous posts of mine if you're curious about how I got started and where I am now.
Connect with me on LinkedIn, or say hi on Twitter! You can also find me at lauralangdon.io.



